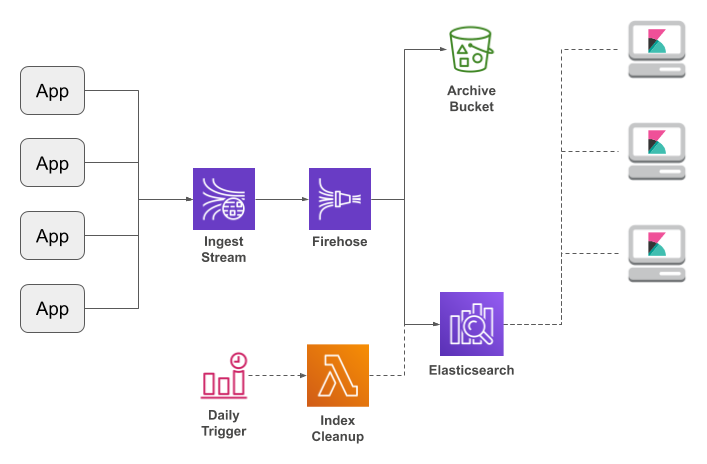
The Amazon ElasticSearch Service is a great solution for in-house logging: it's an easily-configurable search engine with built-in Kibana service to explore your log messages. If you use my Log4J AWS appenders to route application logging into a Kinesis Data Stream and thence through Kinesis Firehose to ElasticSearch, you can have a complete logging framework up and running within a few hours.
But there's one problem: there's no automated purge of old messages. True, you can use Curator, which is the standard management tool for ElasticSearch, but you need to run it from somewhere. Which means your personal PC, or bringing up an EC2 instance just for system management, and both of which are a step away from the "managed for you" promise of AWS.
This post presents an alternative: invoking the ElasticSearch Indices API via a AWS Lambda function that's triggered by a CloudWatch Scheduled Event.
The Lambda Function
Warning: this code is destructive. While I do not believe that it contains any bugs, I do not make a warranty of any kind, and do not not accept any responsibility for your deployment. I strongly recommend that you fully understand and test it before using in a production environment. Use at your own risk.
OK, with that out of the way, the Lambda function is quite simple: it reads the list of indexes from the ElasticSearch cluster, discards those with names that don't match a configured prefix, sorts the rest (relying on the datestamp that Firehose appends to each index), and deletes all but the desired number. Both retrieve and delete are HTTP requests, which is why you do not want to expose your cluster to the open Internet.
Most of the people that I've talked with protect their ElasticSearch cluster with an IP-address-based access policy. Unfortunately, such a policy blocks Lambda, which receives a new IP for every instantiation. You can work around that restriction with signed requests, but that makes the deployment significantly more complex.
I've provided one version of the code that uses signed requests and one that doesn't; pick the one that's most relevant to your environment.
Version 1: unsigned requests
If you have a VPC with a NAT, and your ElasticSearch cluster allows unrestricted requests from the NAT, then this is the version for you. It would also work if your ElasticSearch cluster was running inside the VPC, but as of the time of this writing Firehose can't talk to an in-VPC ElasticSearch cluster, so that case is irrelevant (at least for a Firehose-based logging pipeline).
Under these conditions, we can use the HTTP connection code that's built-in to the Python runtime. And because of that, we can enter the script directly into the AWS Console.
import http.client
import json
import os
def lambda_handler(event, context):
endpoint = os.environ['ELASTIC_SEARCH_ENDPOINT']
numIndexesToKeep = int(os.environ['NUM_INDEXES_TO_KEEP'])
indexPrefix = os.environ['INDEX_PREFIX']
cxt = http.client.HTTPConnection(endpoint);
cxt.request('GET', '/*')
indexResponse = cxt.getresponse()
indexResponseBody = indexResponse.read().decode("utf-8")
if (indexResponse.status != 200):
raise Exception('failed to retrieve indexes: ' + indexResponseBody)
indexData = json.loads(indexResponseBody)
indexNames = sorted([x for x in indexData.keys() if x.startswith(indexPrefix)])
indexesToDelete = indexNames[0 : max(0, len(indexNames) - numIndexesToKeep)]
for idx in indexesToDelete:
cxt.request('DELETE', "/" + idx)
deleteResponse = cxt.getresponse()
deleteResponseBody = deleteResponse.read().decode("utf-8")
if deleteResponse.status == 200:
print("deleted " + idx)
else:
raise Exception("failed to delete " + idx + ": " + deleteResponseBody)
I'm going to assume that you're comfortable creating a Lambda function (if not, go through the tutorial). Here are the key points for setting up your function:
- Pick the "Python 3.6" runtime.
- Configure the environment variables described below.
- You can leave the default memory allotment, but increase the runtime to 30 seconds (HTTP calls may take a long time).
- You will need a role that has the AWS-provided "AWSLambdaVPCAccessExecutionRole" policy. I recommend creating a new role just for the cleanup Lambdas.
- Ensure that the Lambda is configured to run inside the VPC, on a private subnet that routes outbound requests through the NAT.
Version 2: signed requests
If your ElasticSearch cluster limits access by IP and does not permit access from a NAT, you'll need to use this version. It makes arbitrary signed HTTP requests, a feature that is not currently supported by the AWS Python SDK (Boto3). So instead, I use the aws-requests-auth and requests libraries, which means that we have to create a deployment package rather than simply pasting the source code into the AWS Console. And we have to ensure that the Lambda function has permission to update the ElasticSearch cluster. As I said, significantly more complex.
To start, you'll need to create a directory and install dependencies (I'm assuming that you're working on Linux and have Python 3.6 and PIP already installed).
mkdir escleanup
cd escleanup
pip install aws-requests-auth -t `pwd`
Next, the code. Save this in the file
lambda_function.py:
import json
import os
import requests
from aws_requests_auth.aws_auth import AWSRequestsAuth
def lambda_handler(event, context):
endpoint = os.environ['ELASTIC_SEARCH_ENDPOINT']
numIndexesToKeep = int(os.environ['NUM_INDEXES_TO_KEEP'])
indexPrefix = os.environ['INDEX_PREFIX']
auth = AWSRequestsAuth(aws_access_key=os.environ['AWS_ACCESS_KEY_ID'],
aws_secret_access_key=os.environ['AWS_SECRET_ACCESS_KEY'],
aws_token=os.environ['AWS_SESSION_TOKEN'],
aws_region=os.environ['AWS_REGION'],
aws_service='es',
aws_host=endpoint)
indexResponse = requests.get('https://' + endpoint + '/*', auth=auth)
if (indexResponse.status_code != 200):
raise Exception('failed to retrieve indexes: ' + indexResponse.text)
indexData = indexResponse.json()
indexNames = sorted([x for x in indexData.keys() if x.startswith(indexPrefix)])
indexesToDelete = indexNames[0 : max(0, len(indexNames) - numIndexesToKeep)]
for idx in indexesToDelete:
deleteResponse = requests.delete('https://' + endpoint + '/' + idx, auth=auth)
if deleteResponse.status_code == 200:
print("deleted " + idx)
else:
raise Exception("failed to delete " + idx + ": " + deleteResponse.text)
This has to be turned into a ZIP file, along with all of its dependencies:
zip -r /tmp/escleanup.zip .
Now you can create your Lambda function. As with above, we use the "Python 3.6" environment, and start with the default Lambda execution role. In the second page of the creation wizard you will upload the zipfile and set environment variables as below (you can also decided to run in a public subnet of your VPC, but it's fine to leave the Lambda outside your VPC).
The big change with this version is that you should create a new role rather that reuse an existing one, because we're going to grant permissions to that role in the ElasticSearch cluster. If you've configured your cluster to allow IP-based access, then it probably has an access policy that looks like this (only with more IPs):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:us-east-1:123456789012:domain/example/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"54.85.66.156",
"52.3.98.34"
]
}
}
}
]
}
You will need to add a statement that allows access from the role (replacing the ARNs shown here with those for your role and ElasticSearch domain):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/ESCleanup"
},
"Action": "es:*",
"Resource": "arn:aws:es:us-east-1:123456789012:domain/example/*"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "es:*",
"Resource": "arn:aws:es:us-east-1:123456789012:domain/example/*",
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"54.85.66.156",
"52.3.98.34"
]
}
}
}
]
}
Configuration
Like all good Lambda functions, these are configured via environment variables (note: the signed version also uses variables provided by Lambda itself):
-
ELASTIC_SEARCH_ENDPOINT is the endpoint of your cluster, copied from the “Overview” tab on the AWS console.
-
NUM_INDEXES_TO_KEEP is the number of indexes that you want to keep. This is easier than date arithmetic: rather than “keep the last month,” you keep the last 31 days.
-
INDEX_PREFIX identifies the indexes that should be considered for deletion: an ElasticSearch cluster may be used for multiple purposes, and you don't want to destroy another project's data (or the internal .kibana index). Assuming you're populating your ElasticSearch cluster via Kinesis Firehose, use the IndexName from the firehose destination configuration.
Cloudwatch Event Trigger
So you've got the function, but how do you invoke it? This is where CloudWatch Events comes in: in addition to tracking changes to your AWS environment, it can generate scheduled events, which can be used as a trigger for our Lambda.
Use the AWS Console to create a new rule and assign it to your Lambda on a single page. I recommend using a cron expression rather than a fixed rate, so that you can ensure that the cleanup happens when there's not much logging; here's an example that runs at 1 AM EST:
0 6 * * ? *
Testing
As I said earlier, you should test this code before moving to production. If you already have a test cluster that you don't mind playing with, that's the best solution. Alternatively, you could create a copy of your production cluster, although this may be impractical if you have a multi-terabyte cluster (and the instructions take a few tries to get right — I got very good at migrating clusters while writing this post).
Another alternative is to create a small test cluster (a single t2.small.elasticsearch instance, which costs under 4 cents an hour) and manually create empty indexes using curl:
curl -XPUT 'https://search-example-redacted.us-east-1.es.amazonaws.com/example-18-02-18'
As long as the indexes that you create can be sorted and follow a standard naming scheme, the Lambda function will do its thing. You can also adjust the parameters of the CloudWatch Event to perform more frequent deletions, and watch the function execute.
Licensing
Normally I don't mention licensing for code snippets, but I'm planning to use this in my day job and my employment contract requires an explicit license for any not-for-hire code that I use. So, it's licensed under the Apache License 2.0. That said, I really don't want to put a dozen lines of license boilerplate on a 30-line program, and the license says that it can be "attached to" the work. If you use the code, please copy the following boilerplate:
Copyright 2018 Keith D Gregory
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Source and documentation is available at http://blog.kdgregory.com/2018/02/cleaning-up-aws-elasticsearch-indexes.html
Contains example code from https://github.com/DavidMuller/aws-requests-auth