This post is a short introduction to building a logging pipeline based on managed services provided by AWS. I've covered this topic in a presentation for the Philadelphia Java User's Group, and in a much longer article on my website. I've also built such a pipeline, aggregating log messages from (when I left the company) a 200 machine production environment that generated 30 GB of log messages per day.
I'll start with a quick review of why log aggregation is a Good Thing, especially in a cloud deployment:
- You may have many machines writing logs.
To inspect those logs you either need to go to the machines themselves, pull the logs to your workstation, or push them to a centralized location. And your system operations group may have very strong feelings about some of these options.
- You may have many machines running the same application.
To track down a problem, you will have to examine multiple logfiles, and be able to identify which machine they came from.
- You may need to correlate log messages from different applications.
This is a particular problem in a micro-service architecture: your web requests may fail due to a remote service, meaning that you have to correlate logs from different machines.
- Machines regularly shut down.
The promise of cloud deployments is that you can scale-up and scale-down in response to actual load. However, scaling down means terminating the instance, and that means losing all files that haven't been retrieved or pushed to a central location.
There are many ways to approach centralized logging. One of the simplest — and for a small deployment, arguably best — is to ship your logs off to a third-party provider, such as Loggly or SumoLogic. They make it easy to start with centralized logging, providing useful tools at a very reasonable price. The downside is that, as your logging volumes increase, you may move into their “call us” pricing plans.
The standard self-managed solution is the “ELK” stack: Elasticsearch, Logstash, and Kibana. All are products of elastic, which provides these three products in open source versions and makes their money from paid enhancments and consulting.
In my eyes, there are two primary drawbacks to deploying the ELK stack. The main one is that you have to deploy it — and possibly wake up in the middle of the night when one of the nodes in your Elasticsearch cluster goes down. This drawback is answered by Amazon Elasticsearch Service, a managed implementation of Elasticsearch and Kibana. It allows you to bring up or reconfigure an Elasticsearch cluster with a few mouse clicks in the console, and the AWS ops team will fix any failed hardware for you. In exchange, you pay slightly more than a self-hosted solution, and give up some flexibility. For me that's a good deal.
The second drawback to the ELK stack is the “L”: Logstash, and its companion,
Filebeat. To make the ELK stack work, you need to install an agent on each machine: that
agent looks at local logfiles, parses them, and ships a JSON representation off to
Elasticsearch. This isn't too onerous, as long as you format your logfiles to match one
of the out-of-the-box formats, but if you don't you need to write regexes. And you need
to manage the on-host logfiles, using a tool like logrotate.
My solution is to have applications write JSON-formatted messages to a Kinesis Data Stream, where they are picked up and sent to Elasticsearch via Kinesis Firehose.
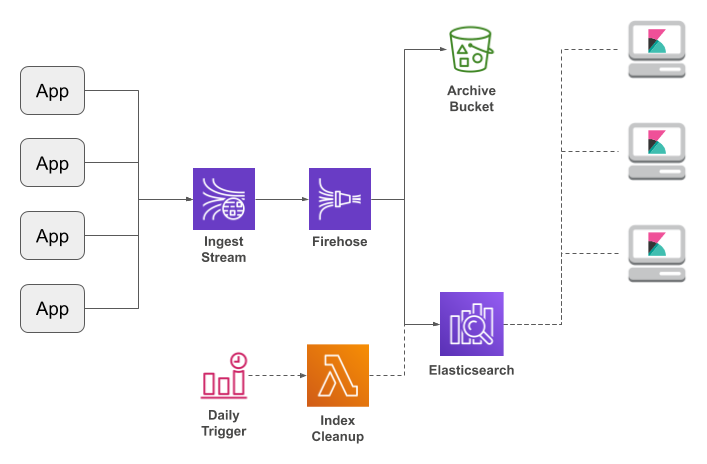
The chief benefit of this architecture — aside from not installing log agents or being woken up in the middle of the night — is scalability. A Kinesis Stream is built from shards, and each shard can accept 1,000 messages or 1 MB per second. As your logging volume increases, you can add shards as needed. Firehose will accommodate the increased throughput by writing to Elasticsearch more frequently. And if you start pushing the limits of your Elasticsearch cluster, you can expand it from the AWS Console.
There is one question remaining: how do the applications write directly to the Kinesis stream? It's actually a rather challenging problem, as writers need to use bulk APIs for performance, but be prepared to resend individual messages. My solution, since I come from a background of Java and Log4J, was to write a Log4J appender library (which also supports other AWS destinations). But I'm not the only person who has had this idea; Googling turned up implementations for Python, .Net, and other languages (I haven't tried them, so am not linking to them).
To recap: if you have a few dozen machines, you'll probably find third-party log aggregators a cost-effective, easy solution. But if your logging volumes are high enough to warrant the cost, this pipeline is an effective alternative to a self-managed ELK stack.
No comments:
Post a Comment